流水線技術是現代計算機系統結構中的關鍵技術之一,它通過將指令或任務分解為多個步驟并行執行,顯著提高了系統的數據處理效率。本文總結流水線技術在數據處理方面的關鍵原理、優勢、挑戰及優化策略。
流水線技術的基本原理
在計算機系統中,流水線技術將指令執行過程劃分為若干獨立的階段,例如取指、譯碼、執行、訪存和寫回。每個階段由專門的硬件單元處理,使得多條指令可以同時在不同階段執行。例如,當一條指令處于執行階段時,下一條指令可能正在進行譯碼,而另一條指令正在被取指。這種并行性通過重疊操作減少了整體執行時間,從而提升了數據處理吞吐量。
流水線技術的優勢
- 提高吞吐量:通過并行執行多個指令階段,流水線技術顯著增加了單位時間內處理的指令數量。例如,在一個五級流水線中,理想情況下每個時鐘周期可以完成一條指令的執行,而非流水線系統可能需要多個周期。
- 資源利用率優化:流水線允許硬件資源(如ALU、寄存器)在不同階段同時工作,減少了空閑時間,從而提高了整體系統效率。
- 適用于大規模數據處理:在數據密集型應用中,如科學計算或圖像處理,流水線可以加速數據流的處理,支持實時或高吞吐量需求。
流水線技術在數據處理中的挑戰
盡管流水線技術帶來了顯著優勢,但在數據處理過程中也面臨一些挑戰:
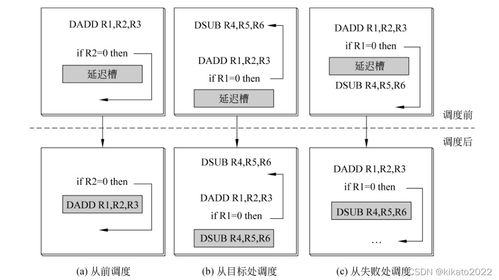
- 數據冒險:當指令之間存在數據依賴關系時,例如一條指令需要等待前一條指令的結果,可能導致流水線停滯(例如,讀寫后寫、寫后讀等數據沖突)。例如,在計算A = B + C和D = A * E時,第二條指令必須等待第一條指令完成,否則可能讀到錯誤的數據。
- 控制冒險:分支指令(如條件跳轉)可能導致流水線中后續指令的預取錯誤,需要清空部分流水線,造成性能損失。這在數據處理密集型循環中尤為常見。
- 結構冒險:當多個指令階段需要同時訪問同一硬件資源(如內存或寄存器文件)時,可能引發資源沖突,從而降低流水線效率。
- 流水線深度與開銷:增加流水線階段數(深度)可以提高并行度,但也引入了更多的寄存器開銷和潛在延遲,尤其在處理短數據序列時,收益可能不顯著。
優化策略與實例
為了克服上述挑戰,計算機系統采用多種優化技術來提升流水線在數據處理中的性能:
- 數據前推:通過硬件機制將數據結果直接從產生階段傳遞到需要它的階段,減少數據冒險帶來的停頓。例如,在執行階段的結果可以立即用于后續指令的譯碼階段,而不必等待寫回。
- 分支預測:使用靜態或動態分支預測算法來預測分支指令的結果,提前加載正確的指令流,從而降低控制冒險的影響。例如,在現代處理器中,基于歷史記錄的分支預測可以顯著提高流水線效率。
- 指令調度:通過編譯器或硬件重排指令順序,減少數據依賴和資源沖突。例如,在循環展開中插入無關指令,以填充流水線氣泡。
- 超流水線與超標量技術:超流水線通過增加流水線階段數進一步提高并行性,而超標量技術則允許每個時鐘周期發射多條指令,共同提升數據處理能力。例如,Intel的x86架構處理器常結合這兩種技術來處理復雜數據任務。
實際應用與未來發展
在現代計算機系統中,流水線技術廣泛應用于CPU、GPU和專用處理器中,以加速數據處理任務。例如,在人工智能和機器學習領域,GPU的并行流水線結構能夠高效處理大規模矩陣運算。隨著異構計算和量子計算的發展,流水線技術可能進一步演化,結合新型架構來解決數據瓶頸問題。
流水線技術是計算機系統結構中提升數據處理效率的核心方法。通過理解其原理、挑戰和優化策略,我們可以設計更高效的系統,滿足不斷增長的數據處理需求。在實際應用中,結合具體場景進行調優,可以最大化流水線的優勢。